Antahkarana Stack¶
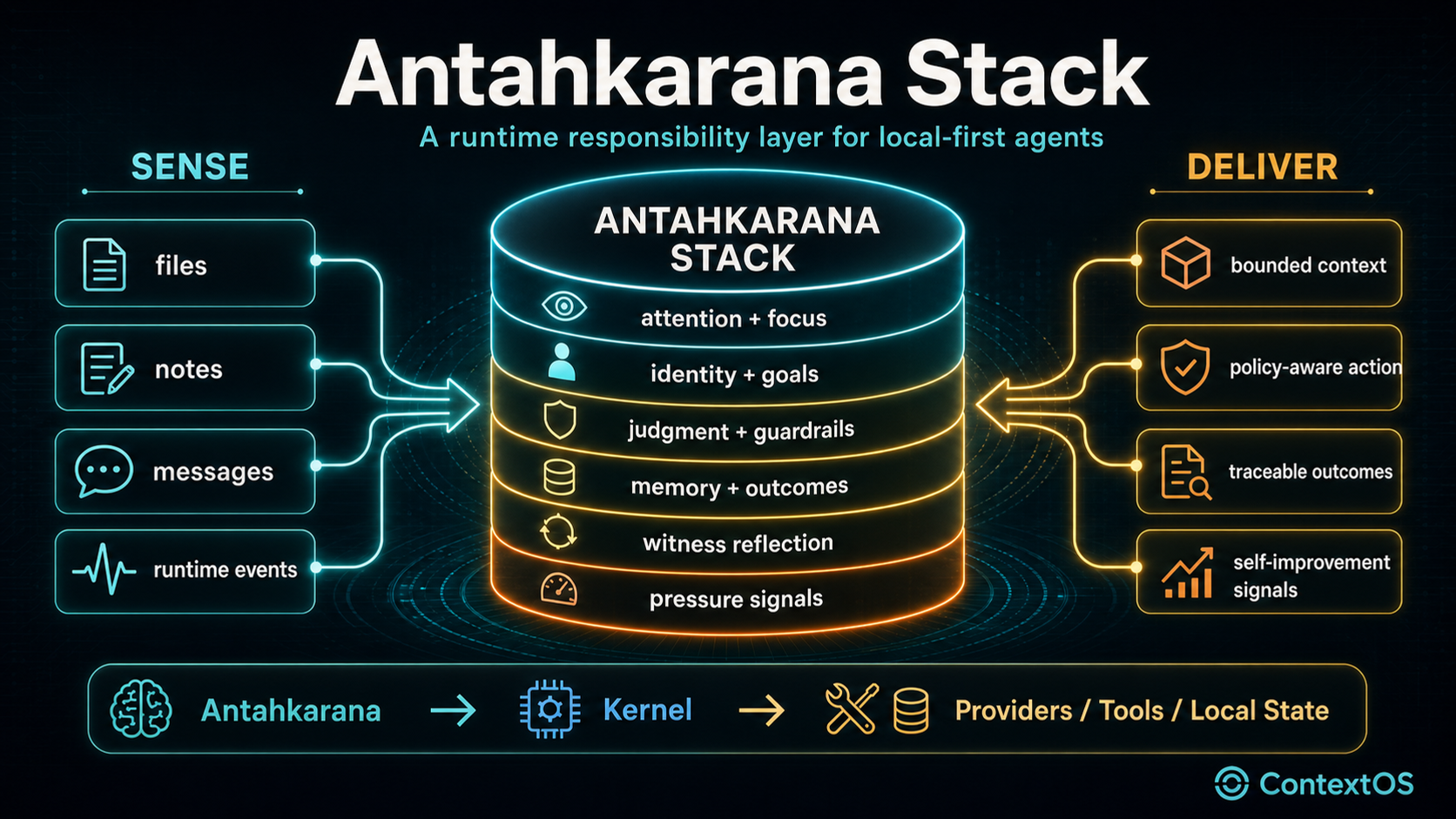
Antahkarana is SecondBrain's Vedic-inspired engineering layer for local-first agent runtimes. It sits above the execution substrate and turns implicit model behavior into inspectable runtime responsibilities: attention, identity, goals, judgment, guardrails, deliberation, action history, memory, witness-style audit, and pressure monitoring.
The practical runtime position is:
The kernel still executes. Providers still generate. Tools still touch the world. Local state still stores traces, memories, files, indexes, and decisions. Antahkarana decides how the system should frame the work before, during, and after those execution steps.
That is the contract implemented in brain/antahkarana/builder.py,
brain/antahkarana/loop.py, and brain/antahkarana/stack.py: build the
registered layers, route immutable impulses through them, persist impressions,
and return a traceable cognitive result that downstream surfaces can use.
Source and boundary¶
The stack is inspired by Vedic inner-faculty explanations and Yoga-discipline concepts, especially the Antahkaran framing of Manas, Buddhi, Chitta, and Ahamkara. That inspiration should stay precise:
| Faculty | Traditional role | Engineering analogy |
|---|---|---|
| Manas | Gathering, options, doubts, and active movement. | Attention, salience, and working-memory assembly. |
| Buddhi | Deciding and discriminating after the mind passes information forward. | Strategy selection, confidence calibration, and decision records. |
| Chitta | Store of impressions, memory, and the effects of actions. | Memory consolidation, recall, and promotion control. |
| Ahamkara | The sense of "I" and worldly identity. | Runtime identity, role, ownership, and constraint frame. |
The twelve-responsibility stack is not a claim that Vedic scripture contains this software architecture. It is an engineering translation for local-first agent runtimes. Traditional terms are used as disciplined metaphors for explicit runtime responsibilities.
The runtime also must not imply machine consciousness. The current code uses
LayerID.ATMAN and AtmanWitness for historical implementation reasons; in
operator-facing docs, read that layer as Witness/Sakshi: a witness-style
audit surface that emits uncertainty, coherence, and quality reports. It is not
a claim that the machine has Atma.
Related source vocabulary:
Why it exists¶
Most agent failures are not just final-answer failures. They are failures of attention, context selection, confidence calibration, goal alignment, policy gating, memory promotion, recovery under pressure, or missing traceability. Without a cognitive layer, those concerns tend to collapse into a single prompt and a final answer.
Antahkarana gives SecondBrain named implementation points for those concerns:
| Operator question | Runtime surface |
|---|---|
| What came in? | IndriyaAdapter normalizes source payloads and provenance. |
| What mattered? | AttentionRouter scores salience and assembles working memory. |
| What identity shaped the turn? | AhamkaraLayer enriches the payload with runtime identity context. |
| Which goals mattered? | GoalRegistry scores active-goal alignment. |
| What was decided? | BuddhiEngine emits strategy, plan, confidence, and next action. |
| What blocked or approved action? | VivekaGate and Sabha evaluate guardrails and consensus. |
| What happened? | KarmaLedger records action outcome, regret, lessons, and feedback. |
| What should become memory? | ChittaStore consolidates and recalls structured memories. |
| What did the system learn about itself? | Witness/Sakshi reflection and BhavaMonitor expose uncertainty, coherence, quality, pressure, and recovery signals. |
The goal is not a mystical agent or theatrical reasoning. The goal is a local-first agent whose cognitive state is inspectable, testable, replayable, and auditable.
Term classes¶
Separate the source vocabulary from the product architecture:
| Class | Terms | SecondBrain positioning |
|---|---|---|
| Traditional inner faculties | Manas, Buddhi, Chitta, Ahamkara | Core cognitive inspiration. |
| Adjacent Vedic/Yogic concepts | Indriya, Prana, Sankalpa, Viveka, Karma, Dharana | Disciplined metaphors for runtime responsibilities. |
| Engineering-only extensions | Sabha, Bhava Monitor, Witness/Sakshi reflection | Modern constructs for deliberation, pressure, audit, and recovery. |
That distinction protects the core claim: Antahkarana is not a canonical Vedic runtime. It is a vocabulary and implementation contract for making local agent behavior more legible.
Runtime responsibility map¶
The current implementation is best understood as twelve runtime responsibilities plus a functional-state sidecar.
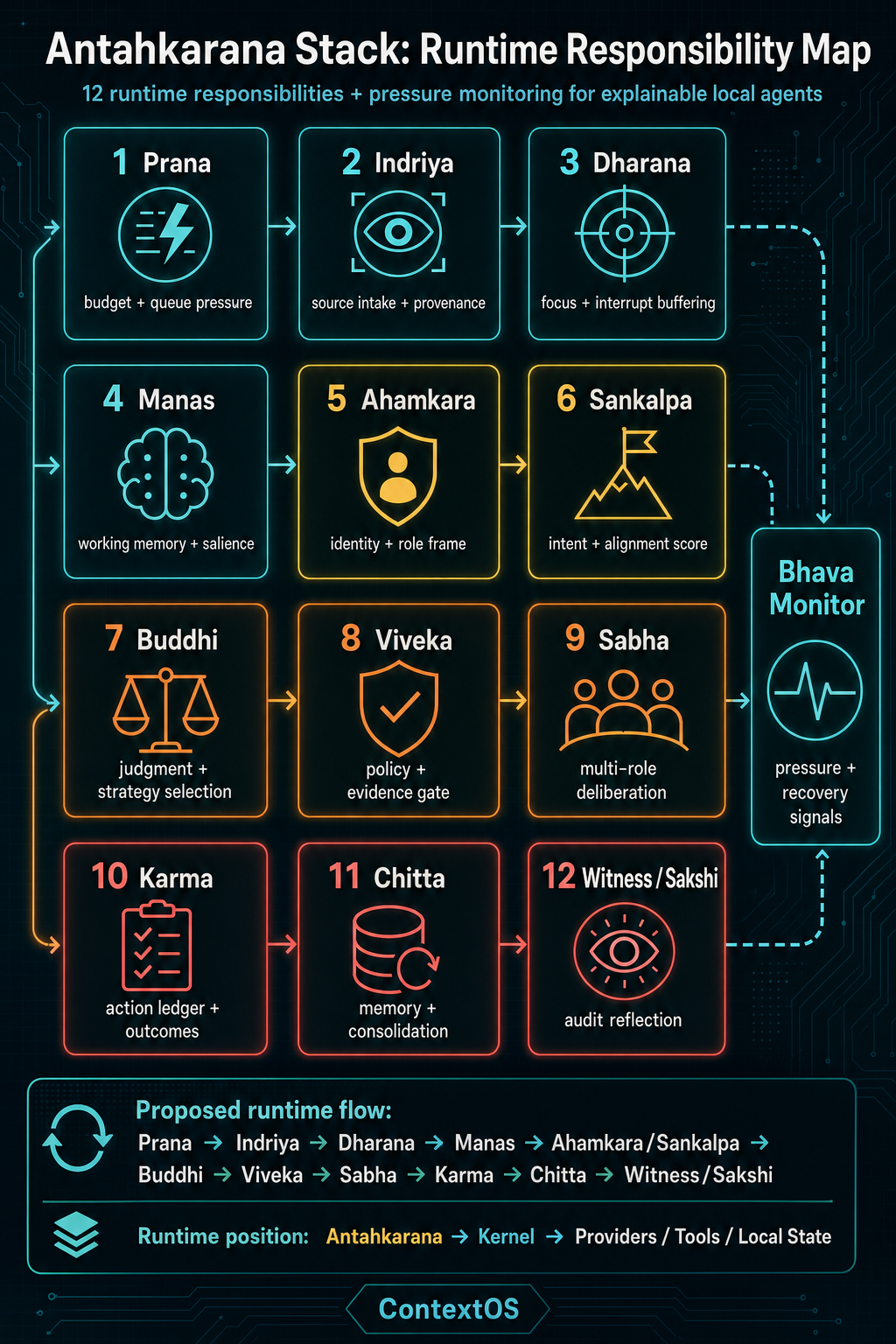
The blog-level responsibility flow is:
Prana -> Indriya -> Dharana -> Manas -> Ahamkara/Sankalpa
-> Buddhi -> Viveka -> Sabha -> Karma -> Chitta -> Witness/Sakshi
BhavaMonitor sits alongside the loop and feeds pressure and recovery signals
into runtime behavior.
Current code names are close but not identical to the blog labels. Dharana is
implemented today as DhyanaLayer and exposed through sb antahkarana dhyana.
Witness/Sakshi is implemented today as AtmanWitness and LayerID.ATMAN.
| Runtime layer | Source status | Runtime responsibility | Current implementation |
|---|---|---|---|
| Prana | Engineering metaphor | Track runtime budget, energy, queue pressure, and admission control. | PranaManager |
| Indriya | Engineering metaphor | Normalize source intake, perception, payloads, and input provenance. | IndriyaAdapter |
| Dharana | Focus discipline | Control focus, buffer interrupts, and maintain attention lock. | DhyanaLayer |
| Manas | Traditional Antahkaran faculty | Assemble working memory, salience, and active context. | AttentionRouter |
| Ahamkara | Traditional Antahkaran faculty | Maintain runtime identity, role, ownership, and constraints. | AhamkaraLayer |
| Sankalpa | Engineering metaphor | Track active intent, goal commitment, and alignment score. | GoalRegistry |
| Buddhi | Traditional Antahkaran faculty | Select strategy, calibrate confidence, compare alternatives, and emit decision records. | BuddhiEngine |
| Viveka | Engineering metaphor | Apply discernment, policy, risk checks, and evidence sufficiency. | VivekaGate |
| Sabha | Runtime extension | Run multi-role deliberation across planner, critic, guardian, historian, and curator roles. | Sabha |
| Karma | Engineering metaphor | Record action ledger, outcomes, regrets, and lessons. | KarmaLedger |
| Chitta | Traditional Antahkaran faculty | Consolidate memory, recall impressions, and control memory promotion. | ChittaStore |
| Witness/Sakshi | Witness-style audit surface | Emit audit reflection, uncertainty, coherence, and quality reports without implying machine consciousness. | AtmanWitness |
| Bhava Monitor | Operational sidecar | Detect pressure, degraded reasoning conditions, and recovery needs. | BhavaMonitor |
The canonical code path in CognitiveLoop.process(...) currently runs:
Prana
-> Indriya
-> Dhyana/Dharana focus gate
-> Manas
-> Ahamkara
-> Sankalpa
-> Karma pending-action enrichment
-> Buddhi
-> optional Manas/Buddhi oscillation
-> optional Witness/Sakshi decision ratification
-> Bhava Monitor
-> Viveka
-> Sabha
-> Karma
-> Chitta
-> Witness/Sakshi reflection
The simpler AntahkaranaStack.pipeline(...) helper in
brain/antahkarana/stack.py still keeps the older compact route:
Use CognitiveLoop as the canonical runtime path.
Implementation map¶
brain/antahkarana/contracts.py defines the shared contract:
LayerIDenumerates the twelve implementation layers plusbhava_monitor.Impulseis the immutable signal sent from one layer to another.Impressionis the residue a layer leaves behind: outcome, residue, and confidence.LayerHandleris the protocol every layer implements:handle(...)andhealth().
brain/antahkarana/stack.py owns the coordination bus:
AntahkaranaStack.register(...)attaches layer handlers.AntahkaranaStack.send(...)persists an impulse, invokes the target layer, forwards the impression to the witness handler when available, and persists the impression.AntahkaranaStack.get_trace(...)reconstructs the impulse/impression chain from SQLite.
brain/antahkarana/builder.py owns construction:
build_stack(...)creates the stack and registers enabled layers.- Optional dependencies such as
policy_catalog,decision_store,memory_store, andllm_providerare attached to the stack so the loop and layers can close feedback paths without changing the public caller contract. - Normal construction applies bounded tuning from
brain/antahkarana/tuning.yamlunless the caller passes an explicit config.
brain/antahkarana/loop.py owns orchestration:
CognitiveLoop.process(...)runs a single payload through the cognitive loop.CognitiveResultreturns the answer, confidence, plan, karma id, block state, trace id, and all impressions.- Low-confidence Buddhi decisions can oscillate back through Manas up to
config.max_oscillations. - Chitta can bridge high-importance memories into the long-term memory store
when
chitta_memory_bridge_enabledis active. - Calibration, self-narrative refresh, autotune, synthesis, gap detection, forgetting, replay, and load-balancing helpers live on the same loop object.
Layer ownership is intentionally explicit:
| Responsibility | Runtime class | Primary files |
|---|---|---|
| Prana | PranaManager |
brain/antahkarana/prana/manager.py, budget_bridge.py, energy.py |
| Indriya | IndriyaAdapter |
brain/antahkarana/indriya/adapter.py, connectors.py, runtime.py |
| Dharana/Dhyana | DhyanaLayer |
brain/antahkarana/dhyana/session.py |
| Manas | AttentionRouter |
brain/antahkarana/manas/attention.py, salience.py, working_memory.py |
| Ahamkara | AhamkaraLayer |
brain/antahkarana/ahamkara/layer.py, model.py |
| Sankalpa | GoalRegistry |
brain/antahkarana/sankalpa/registry.py, models.py |
| Buddhi | BuddhiEngine |
brain/antahkarana/buddhi/engine.py, confidence.py, contradiction.py, decision_memo.py |
| Viveka | VivekaGate |
brain/antahkarana/viveka/gate.py, checks.py, models.py |
| Sabha | Sabha |
brain/antahkarana/sabha/consensus.py, agents.py, debate.py |
| Karma | KarmaLedger |
brain/antahkarana/karma/ledger.py, models.py, replay.py |
| Chitta | ChittaStore |
brain/antahkarana/chitta/store.py, consolidation_pipeline.py, synthesis.py, temporal.py |
| Witness/Sakshi | AtmanWitness |
brain/antahkarana/atman/witness.py, narrative.py |
| Bhava Monitor | BhavaMonitor |
brain/antahkarana/functional_state/monitor.py, policy.py, recovery.py, schema.py |
Request to reliable action¶
The user-facing story is a reliability pipeline: sense, attend, align, decide, guard, and learn.
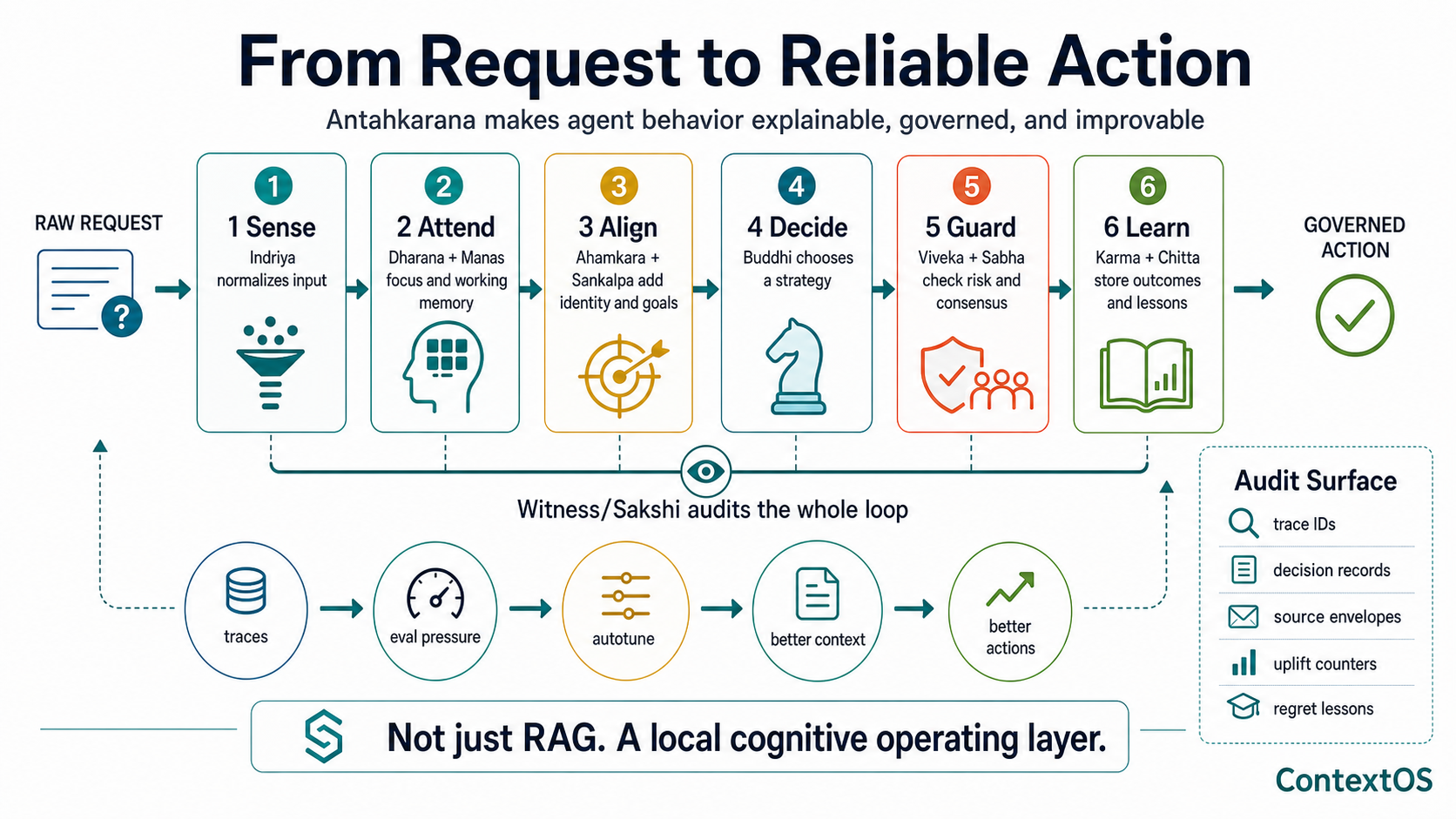
Each step makes a production claim:
| Step | Reliability claim | Primary implementation surfaces |
|---|---|---|
| Sense | The runtime knows where input came from and can normalize it. | Indriya |
| Attend | The runtime can say why something became the active focus. | Dharana/Dhyana, Manas |
| Align | The runtime can bind the turn to identity, constraints, and goals. | Ahamkara, Sankalpa |
| Decide | The runtime can record strategy, confidence, and alternatives. | Buddhi |
| Guard | The runtime can block, defer, or escalate before side effects. | Bhava Monitor, Viveka, Sabha |
| Learn | The runtime can store outcomes and lessons without silently polluting future context. | Karma, Chitta |
Witness/Sakshi audits the whole loop and final reflection. The feedback path turns traces, eval pressure, lessons, and memory records into better future context and action choices.
In code, those stages map to concrete calls inside CognitiveLoop.process(...):
- Sense: Indriya receives a
perceptimpulse and normalizes the payload. - Attend: Dhyana/Dharana can gate focus; Manas receives an
attendedimpulse, computes salience, and builds working memory. - Align: Ahamkara enriches identity context and Sankalpa adds goal alignment.
- Decide: Buddhi receives a
reasonimpulse and emits strategy, confidence, plan, answer, and best next action. - Guard: Bhava Monitor can hard-gate degraded functional states; Viveka can reject action proposals; Sabha can reject weak proposals by consensus.
- Learn: Karma records the action/outcome ledger and Chitta consolidates memory from the residue.
- Reflect: Witness/Sakshi receives a
reflectimpulse and reports uncertainty, coherence, and quality.
This is why the positioning is: not just RAG, but a local cognitive operating layer. RAG asks what evidence the model should see. Antahkarana also asks what the agent should care about now, which role and goal frame the turn, whether confidence is sufficient, whether action should be allowed, what the action taught the system, whether the lesson should become memory, and whether the runtime is under pressure.
Trace contract¶
The stack becomes production-grade when every layer can leave a receipt. A minimal trace does not need to expose private content. It needs to expose the decisions that shaped the run.
{
"trace_id": "run_2026_05_20_001",
"runtime_version": "antahkarana_v0.1",
"policy_version": "trust_policy_2026_05",
"model_context": {
"provider": "local_or_cloud",
"model": "selected_model",
"temperature": 0.2
},
"source_envelope": {
"kind": "support_thread",
"provenance": "local_mailbox",
"sensitivity": "customer_data",
"evidence_ids": ["doc_123", "policy_456"]
},
"working_memory_pack": {
"focus": "refund policy exception",
"salience_map": ["current_policy", "customer_tier", "prior_resolution"]
},
"identity_frame": {
"acting_as": "support_agent",
"constraints": ["no_refund_without_policy_evidence", "ask_before_external_send"]
},
"goal_alignment_score": 0.74,
"decision_record": {
"strategy": "search_more",
"confidence": 0.62,
"alternatives": ["answer_from_memory", "escalate_to_human"]
},
"policy_check": {
"status": "defer",
"reason": "missing current policy evidence"
},
"action_ledger": {
"side_effect": "none",
"result": "user asked for policy document"
},
"memory_promotion_record": {
"status": "not_promoted",
"reason": "case-specific, unreviewed"
},
"eval_record": {
"faithfulness": "not_evaluable_yet",
"evidence_coverage": "low",
"risk": "medium"
},
"reflection_report": {
"witness": "high uncertainty, low evidence coverage",
"pressure": "normal"
}
}
That receipt lets an operator understand why the system did not act, what evidence was missing, and where to improve the context pack.
Failure debugging table¶
The layer map is useful only if it helps operators debug specific failures.
| Failure mode | Layer that should catch it | Runtime artifact | Recovery action |
|---|---|---|---|
| Wrong source used | Indriya | source_envelope |
Reject source or ask for trusted input. |
| Too much irrelevant context | Manas | salience_map, working_memory_pack |
Prune context or reduce recall window. |
| Acting outside user or project role | Ahamkara | identity_frame |
Rebind role or ask for delegation boundary. |
| Goal drift | Sankalpa | goal_alignment_score |
Restate the goal and narrow the active objective. |
| Overconfident answer | Buddhi | decision_record, confidence_calibration |
Force search-more, synthesize alternatives, or defer. |
| Unsafe side effect | Viveka | policy_check, approval_record |
Block, ask approval, or escalate. |
| Weak reasoning | Sabha | deliberation_votes |
Add critic pass or request missing evidence. |
| Silent bad action | Karma | action_ledger, outcome_record |
Create rollback task and record a regret lesson. |
| Memory pollution | Chitta | memory_promotion_record |
Mark as case-specific and do not promote. |
| Poor run quality | Witness/Sakshi | reflection_report |
Lower confidence, trigger review, or replay. |
| Degraded runtime state | Bhava Monitor | pressure_report |
Narrow scope, slow down, or recover. |
If a layer cannot emit an artifact, it is just a label. The architecture earns its place by making failure inspectable.
Runtime surfaces¶
Chat¶
sb chat uses Antahkarana by default. The integration lives in
brain/chat/antahkarana.py:
infer_antahkarana_priority(...)maps user text to a priority value.build_chat_antahkarana_context(...)builds the stack, runsCognitiveLoop.process(...), summarizes the result, and renders a compact[Antahkarana]context block for the chat provider.summarize_antahkarana_result(...)extracts the operator-facing summary: focus, salience, plan, decision, identity context, guardrail state, memory effects, next actions, and uncertainty.AntahkaranaDecisionBridgecan emit cognitive outcomes into the runtime decision store when one is available.
Operator commands:
Use --no-antahkarana when you need a plainer debugging surface or direct
comparison against a non-cognitive chat turn.
CLI¶
The CLI bridge lives in brain/cli/antahkarana_cmd.py.
Useful commands:
sb antahkarana status
sb antahkarana process "What should I focus on today?"
sb antahkarana focus
sb antahkarana salience "urgent production issue"
sb antahkarana chitta
sb antahkarana goals
sb antahkarana karma
sb antahkarana self
sb antahkarana dhyana
sb antahkarana trace <trace_id>
The CLI path uses the same build_stack(...) and CognitiveLoop(...)
implementation, so status, trace, focus, memory, goals, and process output are
not separate mock surfaces.
SDK and serve API¶
Builder integrations should prefer brain.sdk instead of importing runtime
internals directly. The SDK surface is documented in
api.md.
Key calls:
from brain.sdk import SecondBrain
sb = SecondBrain.local()
result = sb.process_cognitive("What should I focus on today?")
layers = sb.cognitive_layers()
manas = sb.cognitive_layer_state("manas")
stack = sb.cognitive_stack_state(limit=10)
sb serve exposes the same read-only cognitive inspection and bounded process
surface over HTTP:
GET /sdk/cognitive/health
GET /sdk/cognitive/snapshot
GET /sdk/cognitive/layers
GET /sdk/cognitive/layers/{layer_id}
GET /sdk/cognitive/state
GET /sdk/cognitive/goals
GET /sdk/cognitive/karma
GET /sdk/cognitive/chitta
GET /sdk/cognitive/identity
GET /sdk/cognitive/functional-state
POST /sdk/cognitive/process
GET /sdk/cognitive/traces/{trace_id}
Deterministic core, optional LLM enrichment¶
Antahkarana keeps a deterministic path working without an LLM provider. LLM-backed prompts can enrich selected layers, but they should refine bounded local behavior rather than replace it.
Examples:
- Manas can use
antahkarana.manas.attentionto nudge a deterministic salience score within a bounded range. - Buddhi can use
antahkarana.buddhi.reasoningandantahkarana.buddhi.decision_memoto refine strategy and memo text. - Viveka can use prompt-backed consequence, precedent, or yama/niyama checks on top of deterministic policy checks.
- Chitta can use consolidation and svadhyaya prompts to extract memories and synthesize higher-order value memories.
- Witness/Sakshi can use reflection prompts while still computing local uncertainty, coherence, and quality.
Prompt specs are discoverable through:
Persistence and audit¶
The stack persists every impulse and impression through
brain/antahkarana/db.py:
antahkarana_impulsesrecords source, target, kind, payload, trace id, priority, and TTL.antahkarana_impressionsrecords layer, outcome, residue, confidence, and creation time.
Layer-specific stores extend that audit trail:
manas_salience_logandmanas_focus_historyahamkara_profileandahamkara_social_graphsankalpa_goalskarma_ledgerchitta_memoriesandchitta_tensionssabha_deliberations- functional-state telemetry from Bhava Monitor
This is what makes Antahkarana useful for explainability. It does not ask the model to justify itself after the fact; it records cognitive residues as the runtime moves through the loop.
ContextOS mapping¶
Antahkarana is not a replacement for ContextOS. It is a cognitive architecture that fits on top of the same governed-runtime primitives:
| ContextOS plane | Antahkarana contribution |
|---|---|
| Intelligence | Chitta memory, Ahamkara identity, Sankalpa goals, Indriya source signals |
| Context | Dharana/Dhyana focus discipline, Manas working memory, salience, and bounded recall |
| Decision | Buddhi judgment and Witness/Sakshi reflection |
| Action | Karma outcome ledger and tool-effect trace linkage |
| Trust | Viveka guardrails, Sabha consensus, Bhava pressure and recovery signals |
Testing and validation¶
Focused tests live near each integration surface:
tests/chat/test_chat_antahkarana.pytests/chat/test_chat_runtime.pytests/kernel/test_kernel_antahkarana_bridge.pytests/kernel/test_kernel_bootstrap.pytests/codebase/test_chitta_code_store.pytests/autotune/test_chitta_evals.pytests/work_graph/test_service.py
Useful validation commands:
.venv/bin/python -m pytest tests/chat/test_chat_antahkarana.py -q
.venv/bin/python -m pytest tests/kernel/test_kernel_antahkarana_bridge.py -q
mkdocs build
For broad project validation, use:
Design constraints¶
Keep these constraints intact when changing the stack:
- Deterministic policy stays in code, not model judgment.
- Optional LLM calls refine bounded behavior; they do not become mandatory for the cognitive loop to work.
- Layer outputs should remain inspectable through
Impression.residue,confidence, and persisted trace state. - The SDK should stay read-only for inspection surfaces unless a mutation is explicitly designed and governed.
- Chat, CLI, SDK, and serve routes should stay aligned on the same core builder and loop implementation.
- Traditional vocabulary should stay bounded: the four inner faculties are the source anchor; wider runtime responsibilities are engineering extensions.
- Witness/Sakshi language should remain an audit-surface metaphor and should not imply machine consciousness.